03. Oct. 2018 by Marek
Retrospective 5.0.0 conquers the container landscape
Overview of containers evolution
Retrospective 5.0.0 is out with a shiny set of entirely new capabilities. Now our tool is no longer restricted to log analysis of local files or those located on remote SSH servers. Retrospective has gained an entirely new functional dimension, as now it is capable of searching and monitoring not only files but also different types of containerized applications.
Along with the advent of microservice architectures, containers have become a common technology for creating, deploying and running applications. Currently Docker is the most popular container platform. It was a pioneering solution and thanks to its widespread adoption has become a de-facto standard for building containerized applications. Docker standardized packaging and distribution by introducing the basic concepts of container image and a container instance that can be spawned on the basis of a given image. However, soon new challenges were identified. It was unsure how containers could be coordinated and scheduled, and how different containers could communicate with each other. Thus new solutions for so-called containers orchestration started to emerge, including, among others, such technologies as: Kubernetes, Mesos and Docker Swarm. These technologies provide a neat abstraction of containers cluster that can be used to solve the mentioned challenges and run container instances in a fully distributed environment.
Containers concepts supported by Retrospective
In the scope of release 5.0.0, Retrospective provides support for working with container images and container instances of Docker and also for probably the most popular container orchestration technology: Kubernetes.
In the containers cluster abstraction of Kubernetes quite a few new concepts are defined. For the sake of brevity we will focus on the concepts that are currently supported in release 5.0.0, namely: Pods, Labels, Selectors, Deployments and Namespaces.
Pod is a basic building block of Kubernetes. It represents a unit of deployment, which might consist of either a single container or a small number of containers that are tightly coupled and that share resources. Besides container(s), a pod encapsulates storage resources, a unique network IP and options specifying how the container(s) should run. Deployment is an object that represents an application running on a Kubernetes cluster. When you create a deployment you may e.g. specify that you want to have three replicas of your application running in the cluster at all times. Thanks to Namespaces, Kubernetes can support multiple virtual clusters backed by the same physical cluster. These virtual clusters are called Namespaces. Names of resources need to be unique within a Namespace but not across Namespaces. Labels are key/value pairs that can be attached to Pods or other Kubernetes objects. Labels can be used to specify attributes of objects that are meaningful and relevant to the users. Thus, Labels can be used to organize and to select subsets of objects. Selecting objects’ subsets on the basis of Labels can be performed using Label Selectors that are the core grouping primitive in Kubernetes.
Diving into Container Browser
When implementing support for container platforms, we have selected an integration approach that is the easiest to configure. In order to interact with Docker and/or Kubernetes technologies it is sufficient to specify (in Retrospective preferences) the path to their command line interfaces (CLIs), namely: docker (docker.exe on Windows) and kubectl (kubectl.exe on Windows). If these CLIs are available on the general OS path then Retrospective will find them without any additional configuration. So, the good news is that you do not need to configure any complicated access details to your containers cluster.
After configuring paths to containers CLIs, you can open the Container Browser that has a similar UI to the Retrospective File Browser and can be used to navigate through Docker and Kubernetes subsystems.
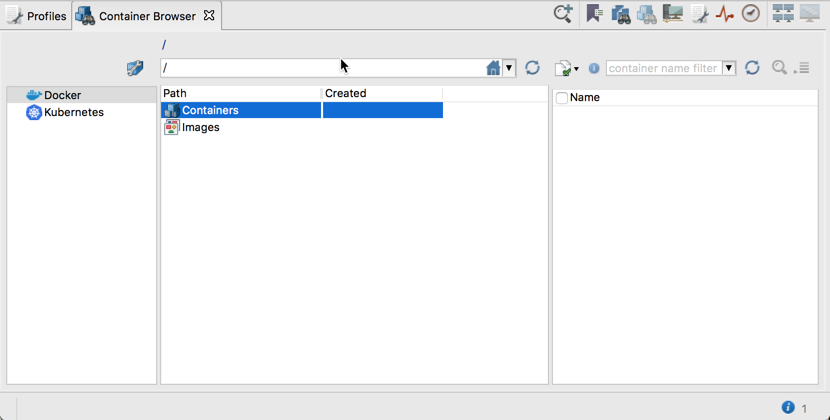
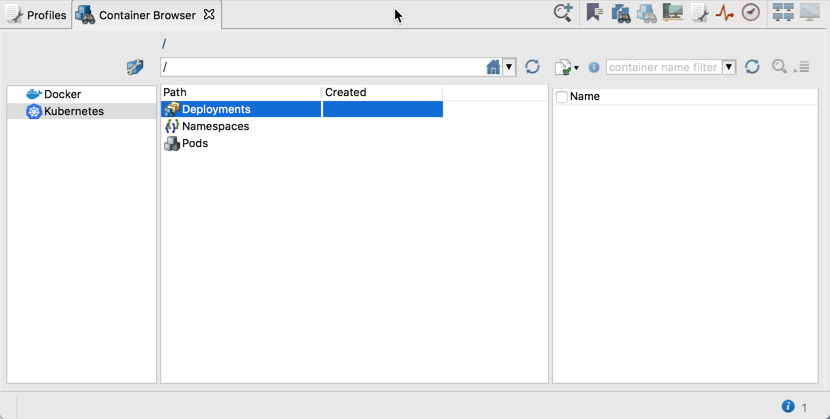
As can be seen in the screenshots above, you can navigate through Containers and Images of Docker and through Deployments, Namespaces and Pods of Kubernetes. This navigation is also available in the Add Container Data Source dialog. Thanks to such navigation structure, you are able to not only specify individual containers or their groups using the Filter Matching Selection – as presented in the screenshot below,
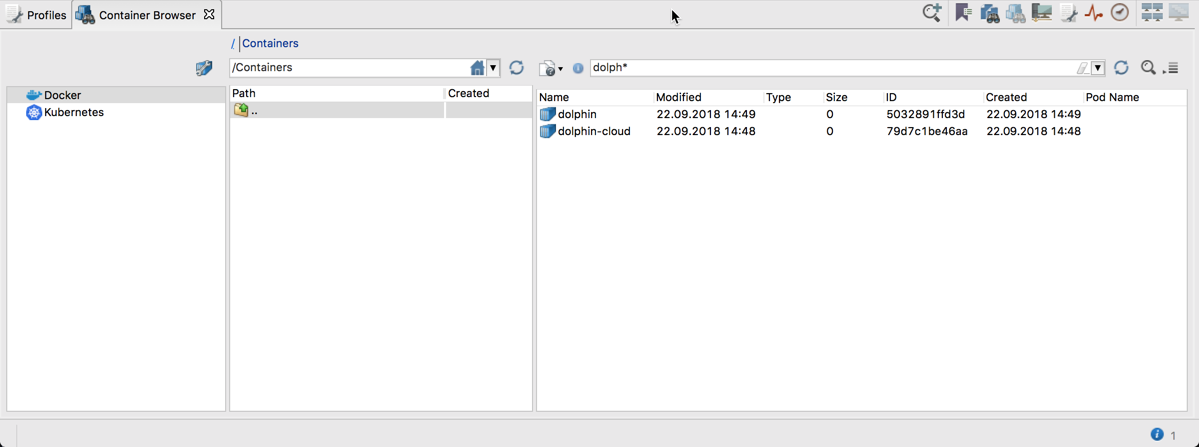
but also, for example, specify a data source that points to all containers of given image:
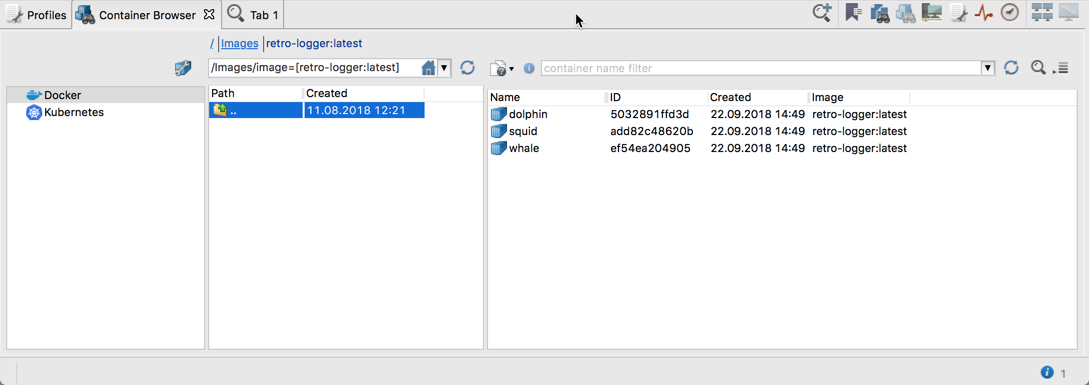
or all containers of given Kubernetes Namespace and given Deployment:
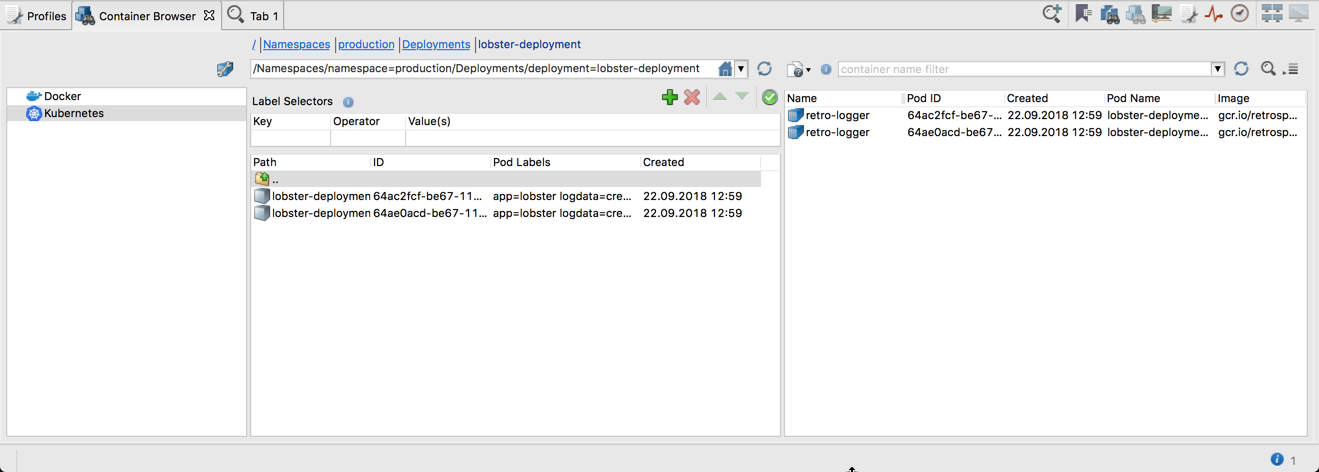
As visible in the screenshot above, when displaying Kubernetes Pods, you see Labels of each Pod and can also configure some Label Selectors that will restrict the number of Pods to those whose Labels are matching the configured Selectors. The other thing that can be noticed in the screenshot above is that, in this example, we are accessing a Kubernetes cluster located in the Google Cloud Engine (GCE) – hostname gcr.io in the Image column points to the google container registry. This shows that Retrospective is able to access any Kubernetes cluster, even if it’s located in the cloud. Retrospective relies here on the proper cluster access configuration of the local kubectl command.
Let’s search and monitor all containers in the neighborhood
One may wonder what does it exactly mean to search or monitor a container using Retrospective. In the container world, there is an assumption that logs of container instance are streamed to standard output and are then handled by the container platform daemon. Thanks to this assumption, in Docker and Kubernetes, you can easily access these logs by executing “docker logs” or “kubectl logs” commands respectively. Retrospective uses these commands to access the logs produced by containers. Thus, searching/monitoring a container simply means searching/monitoring logs that are streamed to the container standard output.
The cool feature of implemented container support is that once your container data sources are configured, Retrospective performs their dynamic evaluation in each searching and monitoring session. Thus, if you have quite dynamic development or even production container environment, you do not need to specify the exact container name, which can change from one deployment to the other. You simply define a data source by specifying e.g. that you are interested in all containers of given image or all containers of given Kubernetes Deployment or even all containers, which Pods match given Label Selectors.
In the case of searching, Retrospective evaluates the data source at the beginning and identifies which containers are currently matching the data source definition. After matching containers are identified, their logs are searched and displayed in the Result Table. In the case of monitoring, Retrospective constantly evaluates the specified data source(s) and when a new matching container is identified, it is monitored for new log entries that were streamed to the container’s standard output. Thanks to this behavior, throughout a monitoring session, Retrospective can easily follow changes in the containers cluster without any need for manual data source reconfiguration.
As can be seen, Retrospective can now easily be used to browse, search and monitor containers in the Docker and Kubernetes platforms. In order to provide you with more control over the searching and monitoring process, Retrospective allows you to set a separate thread pool size for each container subsystem. By setting a thread pool size e.g. to 15, you can simultaneously search up to 15 containers! In the context of monitoring, Retrospective uses threads in an intelligent manner and even if you set the thread pool size to e.g. 3, you could easily simultaneously monitor even up to around 20 or 30 containers (depending on how often their logs are changing) without any thread starvation problems.
Beyond support for containers
Besides a killer feature of container support, release 5.0.0 brings some other cool stuff. First of all, Retrospective can now be used in an unregistered mode. The mode is fully functional and the only drawback is that you are reminded from time to time about the possibility of registering the product. This allows you to have a more thorough verification of the plethora of Retrospective features in your own environment. Once you see for yourself how useful Retrospective is, you can perform the registration.
Release 5.0.0 also provides a new search tab layout ensuring more intuitive access to all the search tab functionalities. Another improvement is related to the custom columns feature provided in the previous release. Now the user is warned when fields detected in a new data source match the ones from an already defined custom column. There are also some improvements in Result Table exporting. The user is provided with additional formatting options when exporting to Excel and can select columns that are exported to Excel or a csv file.
Verdict
Retrospective has always aimed to be the most handy and powerful tool for ad-hoc log analysis. Now, with the strong support for searching and monitoring containerized applications we can confidently state that Retrospective is a true Swiss Army knife for accessing almost any kind of logs. No matter if you throw Retrospective at local files, remote files or at distributed containerized applications, you can stay assured that all the information you need will promptly appear in the Retrospective result table. Unbelievable? Just grab the mighty 5.0.0 release and verify all these bold claims for yourself. We would love to get your feedback!